系统稳定性设计之超时和重试
设置请求超时本身很不起眼,但是需要强调一下超时的意义,“小偏方治大病”。
随着业务越来复杂,业务后台服务会依赖其他业务服务以及基础服务,如消息队列、redis、mysql数据库等。网络总是不可靠,各种服务总是不可靠的。
这些被依赖的服务总会出现各种各样性能不足、功能不可用等情况,此时我们的服务调用其他服务资源时,若没有设置超时,则依赖的服务一个点故障,就可以拖垮整个服务。
如下图所示,若 前端服务 调用 服务1 的接口时,没有设置超时或者API根本就没有超时机制,数据库层通过虚IP实现了高可用,当数据库A不可用,数据库B变成主节点。此时,若 服务1 与 数据库A 之间的链接没有超时机制,那么故障就由于数据库的切换传递到了前端服务。
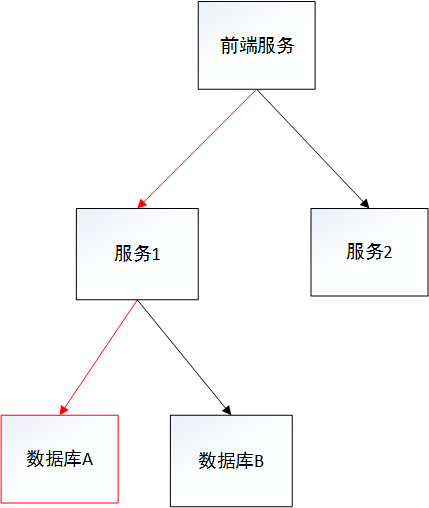
每次 前端服务 的调用 服务1 的API接口,会导致 前端服务 的一个线程被阻塞住,最后,当它所有线程都被阻塞(block)时,前端服务 提供的 服务2 无法对外服务了。整个系统彻底瘫痪。
当然前端服务可能采用异步架构实现,但是只要设置没有超时,最终也避免不了内存等资源耗尽、最终瘫痪的命运。
系统间的调用必须定义明确的超时时间,有了超时机制,系统间的强耦合就变弱了。
重试
后台服务调用其他服务接口,访问超时或者接口返回”我很忙,请稍后“之类的错误码,就需要进行稍后重试。在重试机制中,一般都会使用Exponential Backoff 的策略,也就是所谓的 ” 指数退避 “。
指数退避的本质是,在执行事件时,通过反馈,逐渐降低某个过程的速率,从而最终找到一个合适的速率来处理某个事件。(画外音:这里的反馈其实是负反馈,将控制理论应用到软件系统设计中将极大提高软件系统稳定性,后续有时间再总结一下)
最简单的伪代码如下:
for(nsec =1; nsec < MAXSLEEP/2; nsec <<=1) {
if (work()==0) {
return 成功;
}
sleep(nsec);
}
return 超时失败;
这个算法用在上游的容量大于下游服务容量,可以减少下游服务的压力。由于在智能设备的应用中,可极大减少海量终端对云端服务由频繁重试造成的业务压力。
假设下游超时时间是平均分布的,指数退避的重试时间的期望为:
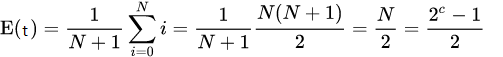
大致为最大超时的一半。按照每一个单位时间重试一次的策略,其重试期望的次数就是E(t)。显然E(t) 远大于c。
为了更好的配合重试机制,需要被调用的下游服务,在即将超过业务容量前,需要通过其对外的API返回业务忙的状态码。请求发起方,调用API获取到业务忙的状态码,则开启指数退避。
指数退避算法也用于以太网的碰撞检测以TCP协议的超时重传,这又是一例将底层协议的思想应用于上层应用的例子。
发表评论